
Summary
You might unknowingly be using an unoptimized dependency which could impact the performance of your app.
Now, it’s easy to get a warning if that happens, at build time,
using the NuGet package UnoptimizedAssemblyDetector:
<PackageReference Include="UnoptimizedAssemblyDetector" Version="0.1.0">
<PrivateAssets>all</PrivateAssets>
</PackageReference>
After you add this NuGet package, a warning will be included in your build if any unoptimized assembly is detected.
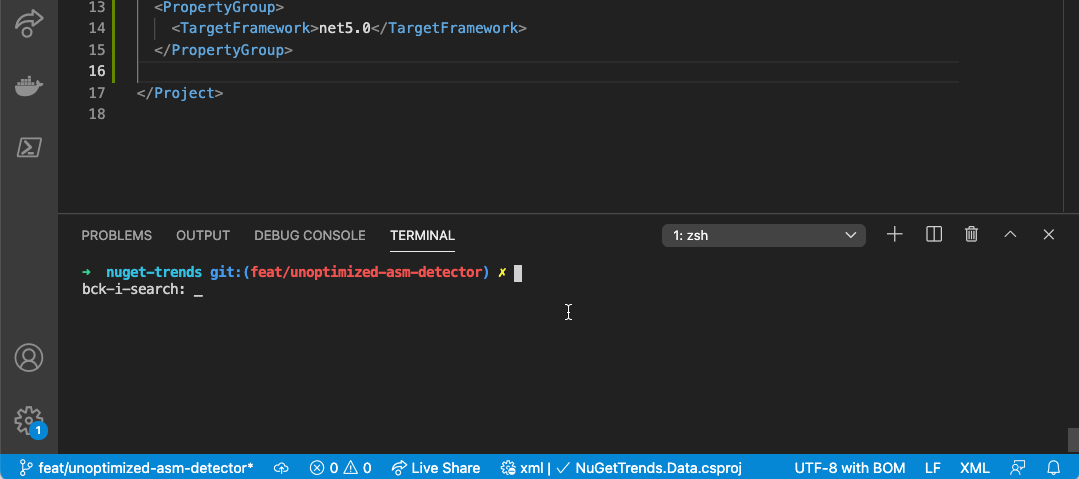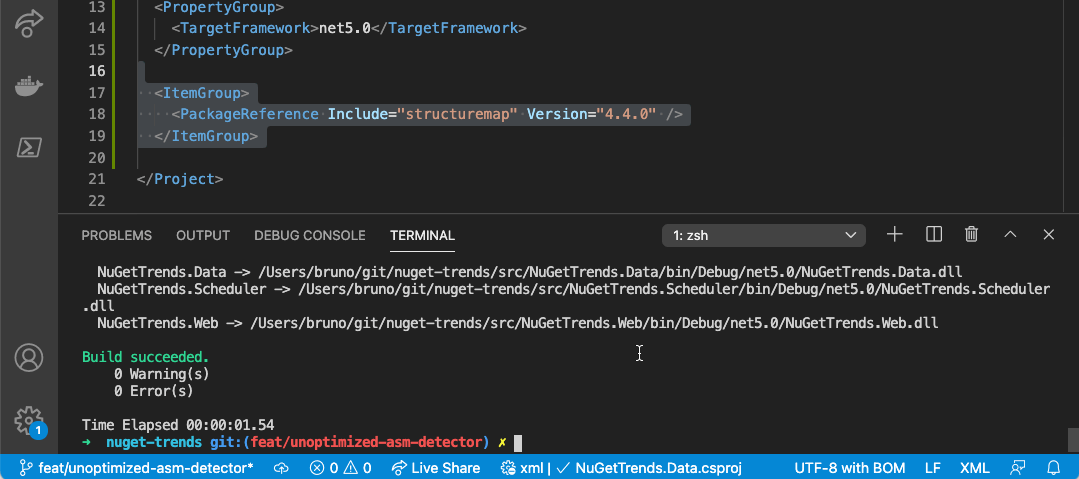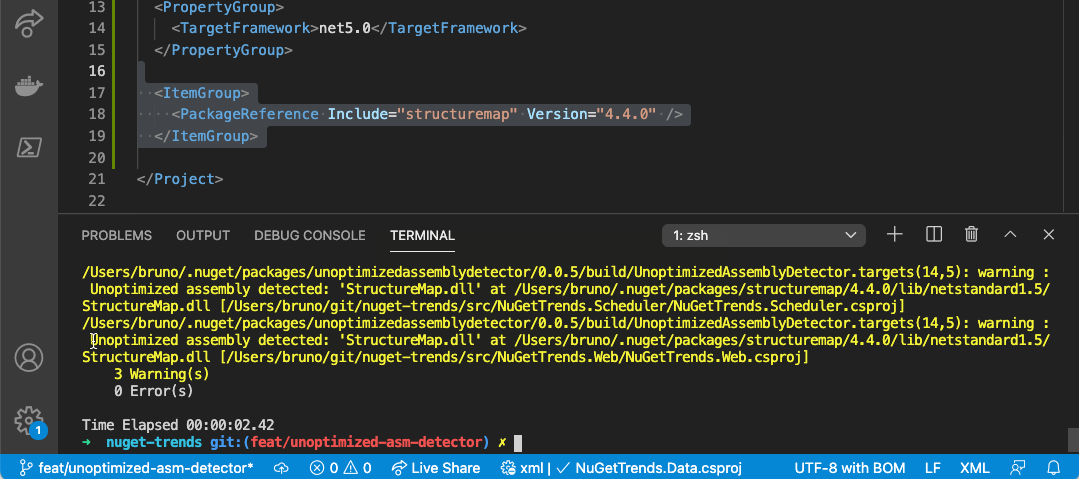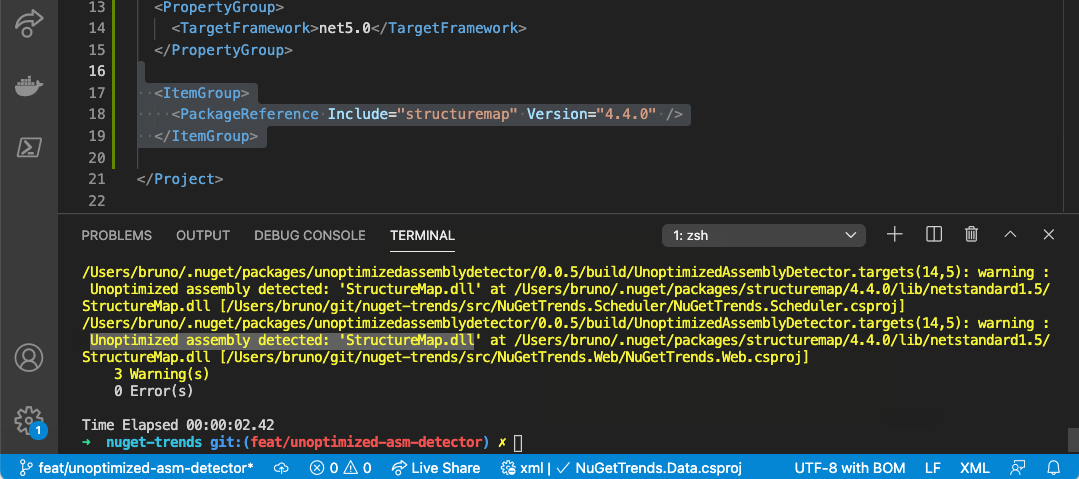
The source code of project is hosted on GitHub ⭐.
What’s the pitfall?
The default build configuration for dotnet pack and dotnet publish is not Release as you might assume or expect.
When publishing NuGet packages to nuget.org, one must explicitly make it a release package, like: dotnet pack -c Release. Without it, the assemblies packed will not be compiled with optimizations.
In this blog post you’ll learn that’s not always the case. Even for those who know, accidents happens and a misconfigured build script can result in a Debug build ending up on nuget.org.
The default value being Debug, which results in unoptimized assemblies, isn’t alone the reason why this is a pitfall.
There’s no warning of any kind from the point you create the NuGet package, through uploading to nuget.org all the way to restoring it for your project.
Why should I care?
If you don’t need convincing, feel free to skip ahead to Sensible defaults.
Benchmarks
No pitfalls when running BenchmarkDotNet in debug mode. It stops you quickly:
➜ dotnet run
// Validating benchmarks:
Assembly UnoptimizedBenchmarks which defines benchmarks is non-optimized
Benchmark was built without optimization enabled (most probably a DEBUG configuration). Please, build it in RELEASE.
If you want to debug the benchmarks, please see https://benchmarkdotnet.org/articles/guides/troubleshooting.html#debugging-benchmarks.
We can force it by using DebugBuildConfig and to illustrate some of the differences between Release and Debug builds,
I adapted a Fibonacci benchmark from this blog post to compare the two:
using System.Collections.Generic;
using System.Linq;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
var summary = BenchmarkRunner.Run(typeof(FibonacciBenchmark).Assembly
#if DEBUG
,new BenchmarkDotNet.Configs.DebugBuildConfig()
#endif
);
public class FibonacciBenchmark
{
[Params(1, 2, 3, 5, 8, 13, 21, 34)]
public int Count { get; set; }
[Benchmark]
public void Fibonacci() => _ = GetFibonacci(Count).ToList();
IEnumerable<int> GetFibonacci(int count)
{
var w = 1; var x = 1;
yield return x;
foreach (var _ in Enumerable.Range(1, count - 1))
{
var y = w + x;
yield return y;
w = x;
x = y;
}
}
}
Debug run
➜ dotnet run -c Debug
BenchmarkDotNet=v0.13.0, OS=macOS Big Sur 11.2.3 (20D91) [Darwin 20.3.0]
Intel Core i7-9750H CPU 2.60GHz, 1 CPU, 12 logical and 6 physical cores
.NET SDK=6.0.100-preview.3.21202.5
[Host] : .NET 6.0.0 (6.0.21.20104), X64 RyuJIT
DefaultJob : .NET 6.0.0 (6.0.21.20104), X64 RyuJIT
BuildConfiguration=Debug
| Method | Count | Mean | Error | StdDev |
|---------- |------ |----------:|---------:|---------:|
| Fibonacci | 1 | 83.99 ns | 1.271 ns | 0.992 ns |
| Fibonacci | 2 | 109.46 ns | 1.460 ns | 1.366 ns |
| Fibonacci | 3 | 124.59 ns | 0.903 ns | 0.845 ns |
| Fibonacci | 5 | 172.64 ns | 0.930 ns | 0.726 ns |
| Fibonacci | 8 | 213.29 ns | 1.019 ns | 0.851 ns |
| Fibonacci | 13 | 315.48 ns | 2.518 ns | 2.103 ns |
| Fibonacci | 21 | 470.91 ns | 2.907 ns | 2.719 ns |
| Fibonacci | 34 | 687.77 ns | 7.792 ns | 6.507 ns |
Release run
➜ dotnet run -c Release
| Method | Count | Mean | Error | StdDev |
|---------- |------ |----------:|---------:|---------:|
| Fibonacci | 1 | 60.52 ns | 0.436 ns | 0.364 ns |
| Fibonacci | 2 | 81.21 ns | 0.465 ns | 0.388 ns |
| Fibonacci | 3 | 93.38 ns | 0.575 ns | 0.449 ns |
| Fibonacci | 5 | 133.85 ns | 0.969 ns | 0.809 ns |
| Fibonacci | 8 | 167.17 ns | 2.574 ns | 3.161 ns |
| Fibonacci | 13 | 242.88 ns | 1.877 ns | 1.567 ns |
| Fibonacci | 21 | 369.98 ns | 5.940 ns | 5.556 ns |
| Fibonacci | 34 | 572.87 ns | 8.560 ns | 8.007 ns |
It’s clear that compiling in Release mode significantly affects the performance of this benchmark.
How much that affects your app? You’d need to measure it. It’s possible that for your app it doesn’t result in any noticeable slow downs. But it possibly can.
Optimizations
Never use the Debug build for benchmarking. Never. The debug version of the target method can run 10–100 times slower.
This came from BenchmarkDotNet’s Good Practices documentation. The impact that it causes to your application might not be as severe or noticeable. Ironically, benchmarking is one of the tools to measure that.
The C# compiler docs state:
The Optimize option enables or disables optimizations performed by the compiler to make your output file smaller, faster, and more efficient. The Optimize option is enabled by default for a Release build configuration. It is off by default for a Debug build configuration.
To go more in depth into what kinds of optimizations are done, lets refer to Eric Lippert, former Principal Engineer in the C# language design team and his blog post on the subject. Which we can read thanks to web.archive.org:
- Expressions which are determined to be only useful for their side effects are turned into code that merely produces the side effects.
- We omit generating code for things like
int foo = 0;because we know that the memory allocator will initialize fields to default values. - We omit emitting and generating empty static class constructors. (Which typically happens if the static constructor set all the fields to their default value and the previous optimization eliminated all of them.)
- We omit emitting a field for any hoisted locals that are unused in an iterator block. (This includes that case where the local in question is used only inside an anonymous function in the iterator block, in which case it is going to become hoisted into a field of the closure class for the anonymous function. No need to hoist it twice if we don’t need to.)
- We attempt to minimize the number of local variable and temporary slots allocated. For example, if you have:
for (int i = …) {…}
for (int i = …) {…}
then the compiler could generate code to re-use the local variable storage reserved for i when the second i comes along. (We eschew this optimization if the locals have different names because then it gets hard to emit sensible debug info, which we still want to do even for the optimized build. However, the jitter is free to perform this optimization if it wishes to.)
- Also, if you have a local which is never used at all, then there is no storage allocated for it if the flag is set.
- Similarly, the compiler is more aggressive about re-using the unnamed temporary slots sometimes used to store results of subexpression calculations.
- Also, with the flag set the compiler is more aggressive about generating code that throws away “temporary” values quickly for things like controlling variables of switch statements, the condition in an “if” statement, the value being returned, and so on. In the non-optimized build these values are treated as unnamed local variables, loaded from and stored to specific locations. In the optimized build they can often be just kept on the stack proper.
- We eliminate pretty much all of the “breakpoint convenience” no-ops.
- If a try block is empty then clearly the catch blocks are not reachable and can be trimmed. (Finally blocks of empty tries are preserved as protected regions because they have unusual behaviour when faced with certain exceptions; see the comments for details.)
- If we have an instruction which branches to
LABEL1, and the instruction atLABEL1branches toLABEL2, then we rewrite the first instruction as a branch straight toLABEL2. Same with branches that go to returns. - We look for “branch over a branch” situations. For example, here we go to
LABEL1if condition is false, otherwise we go toLABEL2.
brfalse condition, LABEL1
br LABEL2
LABEL1: somecode
Since we are simply branching over another branch, we can rewrite this as simply “if condition is true, go to LABEL2":
brtrue condition, LABEL2
somecode
- We look for “branch to nop” situations. If a branch goes to a nop then you can make it branch to the instruction after the nop.
- We look for “branch to next” situations; if a branch goes to the next instruction then you can eliminate it.
- We look for two return instructions in a row; this happens sometimes and obviously we can turn it into a single return instruction.
This text was written a long time ago. And since this writing, Eric Lippert left Microsoft and the C# compiler was rewritten and open sourced. You can browse Roslyn’s repository and you’ll discover that new optimizations are still being suggested and added.
Sensible defaults
I’ve been talking about packaging NuGet with Release configuration then talking about Roslyn optimization.
These two things are not exactly the same (though by default related) and I wish to clarify.
The Release configuration, by default does provide the -optimize+ flag to the C# compiler
but you can achieve the same for example by means of a MSBuild property <Optimize>true</Optimize>.
I hope the quote from the docs I include help make this clear.
Optimize also tells the common language runtime to optimize code at runtime. By default, optimizations are disabled. Specify Optimize+ to enable optimizations. When building a module to be used by an assembly, use the same Optimize settings as used by the assembly. It’s possible to combine the Optimize and Debug options.
This passage from the C# compiler docs isn’t something new, and there has been a lot of debate about whether the default should be changed to Release.
Release as default
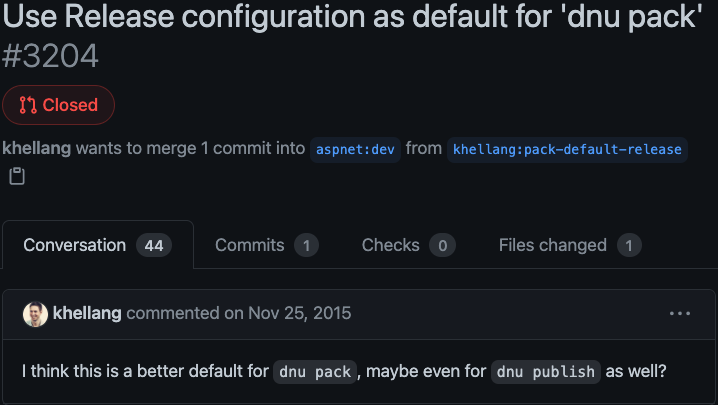
To me, it sounded pretty obvious at first that this should the right thing to do. As it did for a lot of folks on that thread. But it turns out the .NET team has strong and valid opinions to why that shouldn’t be the case.
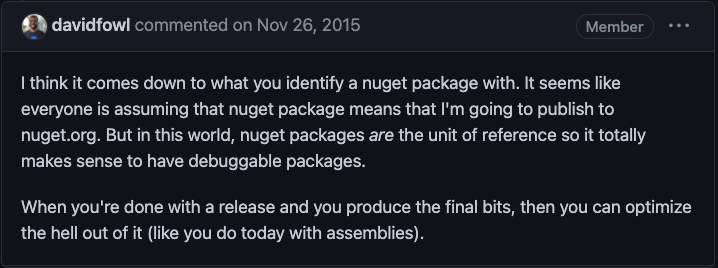
Debug builds on nuget.org
Regardless of which side of the debate you stand, the truth of the matter is that we’re left with packages being published to nuget.org with assemblies compiled without optimization.
StructureMap 4.4.1 is up. No code changes, but corrects the problem of the nuget being built as Debug for 4.3.0 and 4.4.0. Oops on my part.
— jeremydmiller (@jeremydmiller) September 18, 2016
I knew this would happen. I've done it myself and you won't be the last. More debug builds on NuGet ahead. @davidfowl
— Kristian Hellang (@khellang) September 19, 2016
I feel like publishing packages to nuget.org relates a lot to sailing and running aground:
There are three kinds of skippers, those who have run aground, those who will run aground, and those that have but won’t admit it.
Replace skippers with package authors and running aground with publish packages built in debug and there you have it.
Publishing unoptimized bits also happened to Sentry’s SharpRaven SDK back in 2018. If you’re using SharpRaven version 2.3.0, you’re running an unoptimized assembly. I would recommend you upgrade it to 2.3.1 but on that same year that package was replaced by Sentry. Don’t worry, it’s packaged in release mode. Not that you should take my word for it.
In early 2020, I even opened a PR to add this verification to the Sentry SDK for .NET so it would check assemblies being loaded whether they were optimized or not, and send events to Sentry when applicable. But it never felt like the right thing to do. This verification must happen much earlier, at latest during build time. For this reason UnoptimizedAssemblyDetector was born.
My days are numbered
That’s a gloomy heading. It’s the UnoptimizedAssemblyDetector NuGet package talking though, not me.
I built this package in hopes for it to become obsolete one day. Not because I expect the default of dotnet pack to ever change.
Clearly it won’t. But I believe such warnings should be part of NuGet itself.
When you push a NuGet package to nuget.org, it should verify if the managed assemblies under lib/ are indeed compiled with optimization, and if not, it should warn the author.
At the same time, when restoring such package, it should warn the consumer. This part in particular will make UnoptimizedAssemblyDetector redundant.
What else can we do? NuGet Trends has the complete catalog. It could be extended to download the packages and inspect the assemblies in them. With that, create graphs and expose an endpoint to list unoptimized assemblies.
Well that, and ask the NuGet team to add these checks during package upload/restore.
– Cover photo by amirali mirhashemian on Unsplash